基于python的网站后台扫描器
最近没什么事情干,就把之前自己写的python工具写到博客里面
0x00 需要用到的库
- requests: requests 是用Python语言编写,基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。
- threading: 多线程的库,跟网页交互如果单线程会等很多时间。
- time: 统计运行时间的时候要用到。
0x01 程序设计思路
我们需要从字典文件中读入有可能的路径,然后循环访问,遇到返回状态码200代表可以访问,遇到其他的状态码代表不能访问。
0x02 单线程实现
import requests
def guesshtml(url_list,real_list):
for url in url_list:
r = requests.get(url, timeout=30)
if r.status_code==200:
print("存在: "+url)
real_list.append(url)
else:
print("不存在: %s 错误代码: %d"% (url,r.status_code))
return real_list
def add_url(html,dic,url_list):
for line in dic:
line = line.replace('\n','')
url = html + line
url_list.append(url)
return url_list
def main():
html = 'http://www.uuzdaisuki.com/'
dic = open(r"C:\Users\leticia\desktop\dic.txt",'r')
url_list = []
real_list = []
url_list = add_url(html,dic,url_list)
real_list = guesshtml(url_list,real_list)
main()
单线程运行结果: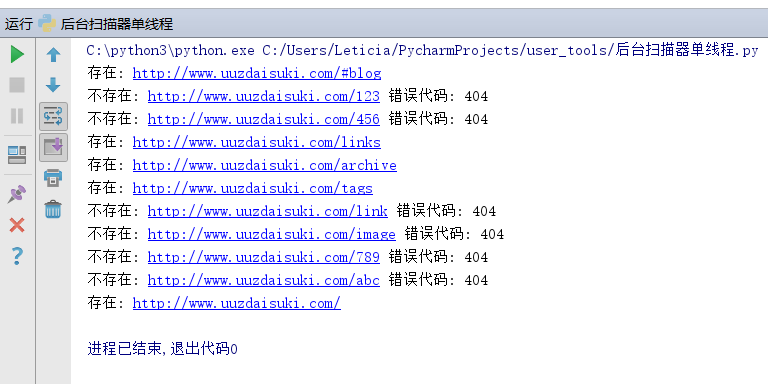
0x03 多线程实现
import requests
from threading import Thread
def guesshtml(url,real_list):
r = requests.get(url, timeout=30)
if r.status_code==200:
print("存在: "+url)
real_list.append(url)
else:
print("不存在: %s 错误代码: %d"% (url,r.status_code))
return real_list
def add_url(html,dic,url_list):
for line in dic:
line = line.replace('\n','')
url = html + line
url_list.append(url)
return url_list
def main():
html = 'http://www.uuzdaisuki.com/'
dic = open(r"C:\Users\leticia\desktop\dic.txt",'r')
url_list = []
real_list = [] #这个暂时没有用到,如果我们需要保存的时候,再用这里。
url_list = add_url(html,dic,url_list)
for url in url_list:
t = Thread(target = guesshtml,args=(url,real_list))
t.start()
main()
多线程运行结果: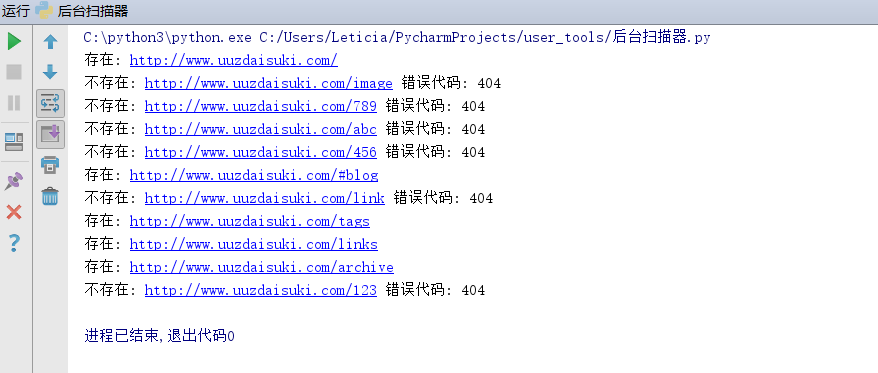
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!