机器学习(1)——定义与分类
0x00 前言
因为假期实习能选择的安全项目大部分都要用到机器学习,而自己对这个领域缺乏了解,所以准备用一段时间专心学习一下。
0x01 机器学习(Machine Learning)
机器学习在不同的领域和不同的学者中有着不同的定义,我认为Alpaydin的定义更偏向于现代机器学习的核心内容:“机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。”(Machine learning is programming computers to optimize a performance criterion using example data or past experience.)
也就是说,机器学习方法是计算机利用已有的数据,得出了某种模型,并利用此模型预测未来的一种方法。
机器学习与人类思考的对比:
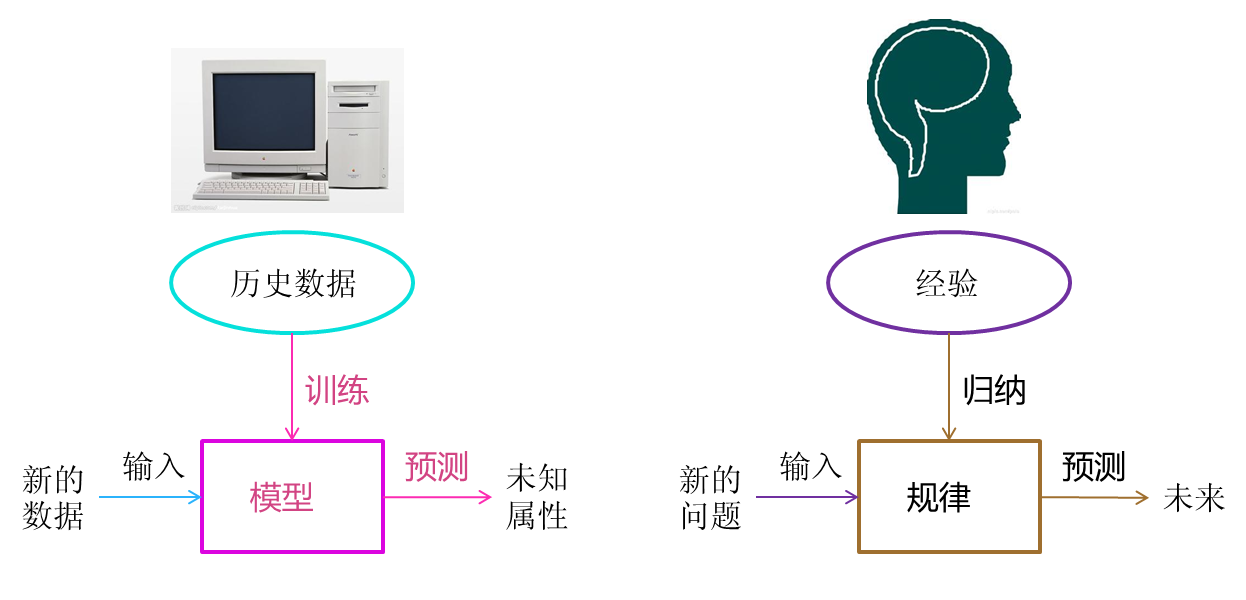
0x02 按照学习策略分类
机器学习的学习策略指学习过程中系统所采用的推理策略。按照学习策略可以将机器学习分为下列几类:
(1)机械学习 (Rote learning)
学习者无需任何推理或其它的知识转换,直接吸取环境所提供的信息。如塞缪尔的跳棋程序,纽厄尔和西蒙的LT系统。这类学习系统主要考虑的是如何索引存贮的知识并加以利用。系统的学习方法是直接通过事先编好、构造好的程序来学习,学习者不作任何工作,或者是通过直接接收既定的事实和数据进行学习,对输入信息不作任何的推理。
(2)示教学习 (Learning from instruction)
学生从环境(教师或其它信息源如教科书等)获取信息,把知识转换成内部可使用的表示形式,并将新的知识和原有知识有机地结合为一体。所以要求学生有一定程度的推理能力,但环境仍要做大量的工作。教师以某种形式提出和组织知识,以使学生拥有的知识可以不断地增加。这种学习方法和人类社会的学校教学方式相似,学习的任务就是建立一个系统,使它能接受教导和建议,并有效地存贮和应用学到的知识。不少专家系统在建立知识库时使用这种方法去实现知识获取。示教学习的一个典型应用例是FOO程序。
(3)演绎学习 (Learning by deduction)
学生所用的推理形式为演绎推理。推理从公理出发,经过逻辑变换推导出结论。这种推理是”保真”变换和特化(specialization)的过程,使学生在推理过程中可以获取有用的知识。这种学习方法包含宏操作(macro-operation)学习、知识编辑和组块(Chunking)技术。演绎推理的逆过程是归纳推理。
(4)类比学习 (Learning by analogy)
利用二个不同领域(源域、目标域)中的知识相似性,可以通过类比,从源域的知识(包括相似的特征和其它性质)推导出目标域的相应知识,从而实现学习。类比学习系统可以使一个已有的计算机应用系统转变为适应于新的领域,来完成原先没有设计的相类似的功能。
(5)基于解释的学习 (Explanation-based learning, EBL)
学生根据教师提供的目标概念、该概念的一个例子、领域理论及可操作准则,首先构造一个解释来说明为什该例子满足目标概念,然后将解释推广为目标概念的一个满足可操作准则的充分条件。EBL已被广泛应用于知识库求精和改善系统的性能。
著名的EBL系统有迪乔恩(G.DeJong)的GENESIS,米切尔(T.Mitchell)的LEXII和LEAP, 以及明顿(S.Minton)等的PRODIGY。
(6)归纳学习 (Learning from induction)
归纳学习是由教师或环境提供某概念的一些实例或反例,让学生通过归纳推理得出该概念的一般描述。这种学习的推理工作量远多于示教学习和演绎学习,因为环境并不提供一般性概念描述(如公理)。从某种程度上说,归纳学习的推理量也比类比学习大,因为没有一个类似的概念可以作为”源概念”加以取用。归纳学习是最基本的,发展也较为成熟的学习方法,在人工智能领域中已经得到广泛的研究和应用。
0x03 按照所获取知识的表示形式分类
(1)代数表达式参数
学习的目标是调节一个固定函数形式的代数表达式参数或系数来达到一个理想的性能。
(2)决策树
用决策树来划分物体的类属,树中每一内部节点对应一个物体属性,而每一边对应于这些属性的可选值,树的叶节点则对应于物体的每个基本分类。
(3)形式文法
在识别一个特定语言的学习中,通过对该语言的一系列表达式进行归纳,形成该语言的形式文法。
(4)产生式规则
产生式规则表示为条件—动作对,已被极为广泛地使用。学习系统中的学习行为主要是:生成、泛化、特化(Specialization)或合成产生式规则。
(5)形式逻辑表达式
形式逻辑表达式的基本成分是命题、谓词、变量、约束变量范围的语句,及嵌入的逻辑表达式。
(6)图和网络
有的系统采用图匹配和图转换方案来有效地比较和索引知识。
(7)框架和模式(schema)
每个框架包含一组槽,用于描述事物(概念和个体)的各个方面。
(8)计算机程序和其它的过程编码
获取这种形式的知识,目的在于取得一种能实现特定过程的能力,而不是为了推断该过程的内部结构。
(9)神经网络
这主要用在联接学习中。学习所获取的知识,最后归纳为一个神经网络。
(10)多种表示形式的组合
有时一个学习系统中获取的知识需要综合应用上述几种知识表示形式。
0x04 按照学习形势分类
(1)监督学习(supervised learning)
监督学习,即在机械学习过程中提供对错指示。一般实在是数据组中包含最终结果(0,1)。通过算法让机器自我减少误差。这一类学习主要应用于分类和预测 (regression & classify)。监督学习从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。
常见的监督学习算法:
线性回归,逻辑回归,神经网络,SVM
(2)非监督学习(unsupervised learning)
非监督学习又称归纳性学习(clustering)利用K方式(Kmeans),建立中心(centriole),通过循环和递减运算(iteration&descent)来减小误差,达到分类的目的。
常见的无监督学习算法:
聚类算法,降维算法
0x05 机器学习的范围
模式识别
模式识别=机器学习。两者的主要区别在于前者是从工业界发展起来的概念,后者则主要源自计算机学科。在著名的《Pattern Recognition And Machine Learning》这本书中,Christopher M. Bishop在开头是这样说的“模式识别源自工业界,而机器学习来自于计算机学科。不过,它们中的活动可以被视为同一个领域的两个方面,同时在过去的10年间,它们都有了长足的发展”。
数据挖掘
数据挖掘=机器学习+数据库。这几年数据挖掘的概念实在是太耳熟能详。几乎等同于炒作。但凡说数据挖掘都会吹嘘数据挖掘如何如何,例如从数据中挖出金子,以及将废弃的数据转化为价值等等。但是,我尽管可能会挖出金子,但我也可能挖的是“石头”啊。这个说法的意思是,数据挖掘仅仅是一种思考方式,告诉我们应该尝试从数据中挖掘出知识,但不是每个数据都能挖掘出金子的,所以不要神话它。一个系统绝对不会因为上了一个数据挖掘模块就变得无所不能(这是IBM最喜欢吹嘘的),恰恰相反,一个拥有数据挖掘思维的人员才是关键,而且他还必须对数据有深刻的认识,这样才可能从数据中导出模式指引业务的改善。大部分数据挖掘中的算法是机器学习的算法在数据库中的优化。
统计学习
统计学习近似等于机器学习。统计学习是个与机器学习高度重叠的学科。因为机器学习中的大多数方法来自统计学,甚至可以认为,统计学的发展促进机器学习的繁荣昌盛。例如著名的支持向量机算法,就是源自统计学科。但是在某种程度上两者是有分别的,这个分别在于:统计学习者重点关注的是统计模型的发展与优化,偏数学,而机器学习者更关注的是能够解决问题,偏实践,因此机器学习研究者会重点研究学习算法在计算机上执行的效率与准确性的提升。
计算机视觉
计算机视觉=图像处理+机器学习。图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式。计算机视觉相关的应用非常的多,例如百度识图、手写字符识别、车牌识别等等应用。这个领域是应用前景非常火热的,同时也是研究的热门方向。随着机器学习的新领域深度学习的发展,大大促进了计算机图像识别的效果,因此未来计算机视觉界的发展前景不可估量。
语音识别
语音识别=语音处理+机器学习。语音识别就是音频处理技术与机器学习的结合。语音识别技术一般不会单独使用,一般会结合自然语言处理的相关技术。目前的相关应用有苹果的语音助手siri等。
自然语言处理
自然语言处理=文本处理+机器学习。自然语言处理技术主要是让机器理解人类的语言的一门领域。在自然语言处理技术中,大量使用了编译原理相关的技术,例如词法分析,语法分析等等,除此之外,在理解这个层面,则使用了语义理解,机器学习等技术。作为唯一由人类自身创造的符号,自然语言处理一直是机器学习界不断研究的方向。按照百度机器学习专家余凯的说法“听与看,说白了就是阿猫和阿狗都会的,而只有语言才是人类独有的”。如何利用机器学习技术进行自然语言的的深度理解,一直是工业和学术界关注的焦点。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!