python爬虫暴力破解网站登陆密码(一)
python爬虫暴力破解网站登陆密码(一)
本来准备一次写完这篇博客,但是写出主干后发现有很多重要的东西没有提到,所以就分成两篇写,这篇写基础操作,下一篇加上验证码处理和多线程处理模块。
0x00 robot.txt
在写爬虫爬取某个网站之前,我们应该去了解这个网站的robot.txt。那什么是robot.txt呢?简单的说,就是网站的所有者为了让爬虫了解爬取该网站的时候存在哪些限制。虽然这些限制只是建议,但是如果你的爬虫不遵守这些限制,很容易会被网站所封禁。
下图为IBM官方网站的robot.txt,我们写爬虫的时候,应该尽量遵守规定。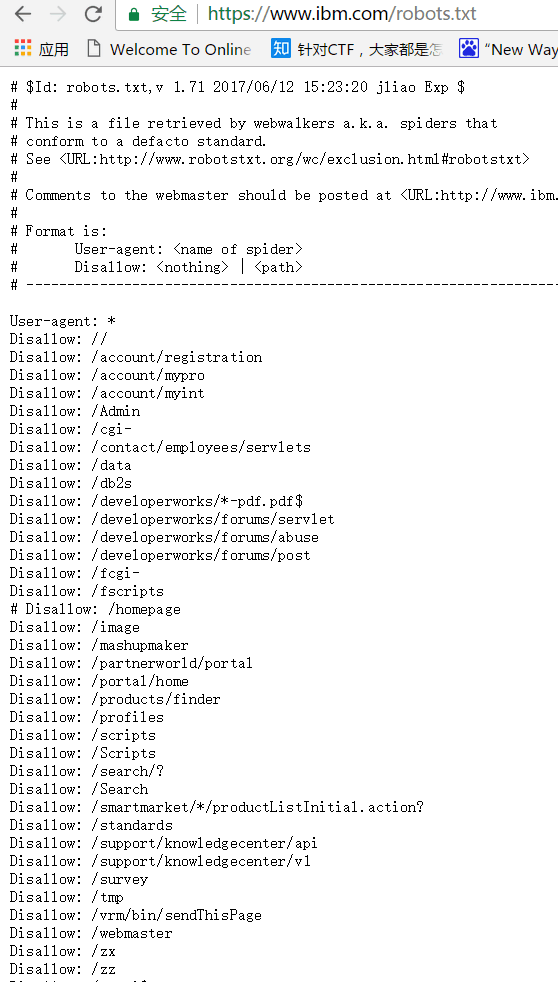
下面给出几种写法示例:
- 允许所有的robot访问
1
2
3
4
5User-agent: *
Allow: /
或者
User-agent: *
Disallow: - 禁止所有搜索引擎访问网站的任何部分
1
2User-agent: *
Disallow: / - 仅禁止Baiduspider访问您的网站
1
2User-agent: Baiduspider
Disallow: / - 仅允许Baiduspider访问您的网站
1
2User-agent: Baiduspider
Disallow: - 禁止spider访问特定目录0x01 伪造header
1
2User-agent: *
Disallow: /tmp/
网站防采集的前提就是要正确地区分人类访问用户和网络机器人,方法之一就是查看你的http请求头,我们为了让自己的爬虫看起来更像是人类用户,就需要对header进行伪造。
伪造header成什么样最好呢?当然是伪造成自己手动访问时候的样子最好。这里我们就能用到Firefox中的一个扩展工具——HttpFox(也可以用Chrome开发者模式直接查看),利用这个工具,我们能抓取我们用Firefox访问网站过程的数据包,然后查看这个数据包,就可以看到我们手动访问时的header,然后使用python的requests库进行伪造。
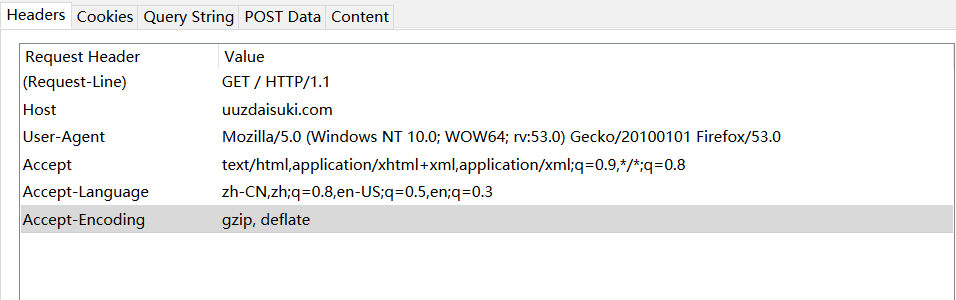
代码中hea的部分就可以照着上图写成这种格式:
1 | |
0x02 填写data并登陆
既然要破解登陆密码,那前提肯定要做到登陆,我们手动登陆的时候当然是输入账号,输入密码,然后点击提交。可是爬虫工作时,看到的和我们不一样,这个时候账号密码应该怎么传入、登陆操作该怎么进行呢?这个时候再一次用到了Httpfox(同样可以用Chrome开发者模式直接查看),上次我们手动输入时,传入的数据在Httpfox中也被抓取了,照着他的样子填好data,然后我们使用requests中的post命令传入data获取一个cookie,然后再通过cookies访问下一个网站,就实现了爬虫的登陆。
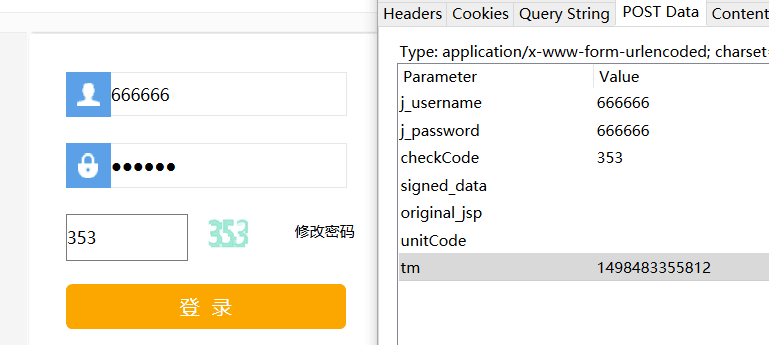
如这个网站,两种方法都可以看到要传递的数据,那么填写的时候就要写成这种格式:
1 | |
0x03 测试
这里用一个ctf环境先做一个小脚本进行测试,这道题密码是五位纯数字,生成字典的方法之前破解压缩包的时候已经讲过不在赘述,代码如下。
1 | |
结果如下:
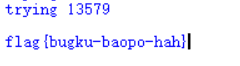
这个脚本的雏形就有了,可以爆破出结果,但是还存在速度很慢,遇到验证码无法进行等问题,下一节再加上验证码处理和多线程处理的模块,解决了这几个问题,就可以用来处理常见的网站了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!