机器学习(3)——逻辑回归
0x00 逻辑回归(Logistic Regression)
逻辑回归就是这样的一个过程:面对一个回归或者分类问题,建立代价函数,然后通过优化方法迭代求解出最优的模型参数,然后测试验证我们这个求解的模型的好坏。
Logistic回归虽然名字里带“回归”,但是它实际上是一种分类方法,主要用于两分类问题(即输出只有两种,分别代表两个类别)
回归模型中,y是一个定性变量,比如y=0或1,logistic方法主要应用于研究某些事件发生的概率。
0x01 逻辑回归模型
它的核心思想是,如果线性回归的结果输出是一个连续值,而值的范围是无法限定的,那我们有没有办法把这个结果值映射为可以帮助我们判断的结果呢。而如果输出结果是 (0,1) 的一个概率值,这个问题就很清楚了。
在数学上有sigmoid函数可以帮助我们实现这一思想。
sigmoid函数表达式:
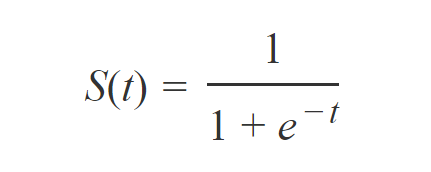
二元逻辑回归时,将t换成ax+b,可以得到二元逻辑回归模型的参数形式:

sigmoid函数图形:

其中,如果是二元回归时,我们P(x)的值可以理解为某一分类概率的大小,如果P(x)值为0.6,代表输出为1的概率是60%,补集部分是输出为0的概率40%。
此时P(x)的值越小,而分类为0的的概率越高,反之,值越大的话分类为1的的概率越高。如果靠近临界点即靠近0.6时,分类准确率会下降。
0x02 决策边界(decision boundary)
决策边界就是能够把样本正确分类的一条边界,从图像上可以直观的看到
如线性决策边界:

非线性决策边界:

在上面二元逻辑回归的例子中,我们用y表示输出的离散值0或1,写为函数形式为:

然后我们逻辑函数g要做到,在输入大于等于零时,输出大于等于0.6;在输入小于零时,输出小于等于0.6。即:
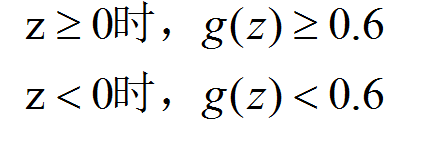
决策边界是假设函数的属性,由参数决定,而不是由数据集的特征决定。
0x03 成本函数(Cost Function)
线性回归中也说过成本函数,也叫代价函数,在逻辑回归中,我们也需要定义成本函数对其取值的好坏进行评估。
而逻辑回归如果取用和线性回归一样的方式计算成本函数,那么图形是“非凸”的。

这样就会产生很多个局部最小值,无法使用梯度下降算法。所以我们需要一个新的成本函数。
在逻辑回归中,损失函数是用来估计预测值(y^(i))与期望输出值(y(i))之间的差异。
统计学习中常用的损失函数有以下几种:
(1) 0-1损失函数(0-1 loss function):
(2) 平方损失函数(quadratic loss function)
(3) 绝对损失函数(absolute loss function)
(4) 对数损失函数(logarithmic loss function) 或对数似然损失函数(log-likelihood loss function)
损失函数越小,模型就越好。
所以在逻辑回归中,为了保证全局收敛,我们采用对数似然损失函数。

也就是说,如下两个情况:
如果是正确答案为y=1的情况:

当y=1, 则Cost=0,也就是预测的值和真实的值完全相等的时候成本为0;但是如果y=0,Cost接近无穷大,也就是说此时成本会非常大。
如果是正确答案为y=0的情况:
当y=0, 则Cost=0,也就是预测的值和真实的值完全相等的时候成本为0;但是如果y=1,Cost接近无穷大,也就是说此时成本会非常大。
0x04 简化成本函数
在上面式子中,由于y 只能等于0或1,所以可以将逻辑回归中的Cost function的两个公式合并可以将我们的成本函数的两个条件案例压缩成一个案例:

当y等于1时,第二项(1-y)log(1- hθ(x))将为零,并且不会影响结果。如果y等于0,则所述第一术语-ylog(1-hθ(X))将为零,且不会影响结果。
所以最终整个逻辑回归的成本函数如下:

0x05 梯度下降
与线性回归相似,这里我们同样采用梯度下降算法来学习参数
迭代函数

算法就是迭代这个公式每次更新参数值,上篇已经详细说过

0x06 优化(Advanced Optimization)
优化算法除了梯度下降算法外,还包括:
- Conjugate gradient method(共轭梯度法)
- Quasi-Newton method(拟牛顿法)
- BFGS method
- L-BFGS(Limited-memory BFGS)
后二者由拟牛顿法引申出来,与梯度下降算法相比,这些算法的优点是:
- 1.不需要手动的选择步长
- 2.通常比梯度下降算法快
因为算法太过复杂,我们不需要手动编写代码,只需要在库中调用相关的函数即可。
0x07 多分类问题(Multiclass Classification: One-vs-all)
我们大多时候遇到的分类并不止两类,这个时候就产生了多分类问题。
首先,二分类问题时候图形如下:

那么多分类问题的图形就如下:

对于多分类问题,我们可以将其先看成二分类问题,保留一类之后剩余的划作另一类。
对上面的三类问题,我们需要三次划分,如图:

最终的One-vs-all方法:
对于每一个类i训练一个逻辑回归模型的分类器,并且预测 y = i时的概率。
对于一个新的输入变量x,分别对每一个类进行预测,取概率最大的那个类作为分类结果。
也就是说,如果输入一个x,此时分类器A概率为0.3,分类器B概率为0.4,分类器C概率为0.5,那么他就属于C这个分类。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!