正则表达式导致的redos问题
前言
正则表达式是非常受欢迎的字符串处理工具,在各种场景都有着广泛的用途,而不规范的使用也会引发一些安全问题,比如针对运算资源的攻击:redos,它就是一种错误使用正则表达式导致运算量随待匹配字符指数级增长的安全问题。
贪婪和非贪婪匹配
正则表达式有很多重复运算符,而使用这些重复运算符匹配时往往会有不同答案都符合条件,正则表达式在默认情况下会选择贪婪匹配的方式。
| 符号 | 用途 |
|---|
- | 匹配前面的子表达式零次或多次
- | 匹配前面的子表达式一次或多次
. | 匹配除换行符 \n 之外的任何单字符
? | 匹配前面的子表达式零次或一次
例如有正则a.*b,有待匹配字段accbccb,看似accb和accbccb两种结果都符合正则,但是由于正则表达式默认选择贪婪匹配模式,会尽可能多的匹配结果,就会匹配出accbccb的结果。
如果我们要得到accb的结果,就需要使用?运算符进行非贪婪匹配,构造正则表达式a.*?b
正则表达式引擎
正则表达式引擎有两种方式实现:DFA 自动机(Deterministic Final Automata 确定型有穷自动机)和 NFA 自动机(Non deterministic Finite Automaton 不确定型有穷自动机)。
其中DFA 自动机的时间复杂度是线性的,更加稳定,但是功能有限。而 NFA 的时间复杂度比较不稳定,复杂度取决于正则表达式的书写。但由于NFA自动机的功能强大,被多种编程语言广泛使用,如python、java、perl、php、ruby等编程语言的正则表达式,都使用了NFA方式去实现。
正则表达式回溯
NFA的正则表达式引擎在匹配时为了满足尽可能多的功能,复杂度也会更高,也就是需要走的步数会很多。
比如我们使用a*b对aaaaaa做一次正则匹配,我们的大脑可以一眼看出字符串中没有b,无匹配结果,但是正则表达式不会这样处理,他会一步一步的来尝试。
首先他会一步步匹配到aaaaaa,然后发现最后一位不是b,不匹配,回溯。
接着去匹配aaaaa,最后一位不匹配,回溯
接着去匹配aaaa,最后一位不匹配,回溯
接着去匹配aaa,最后一位不匹配,回溯
接着去匹配aa,最后一位不匹配,回溯
接着去匹配a,最后一位不匹配,回溯
发现无匹配结果
然后又会从第二位a开始,重新经历上述过程进行匹配,再从第三位,第四位开始,直到最后一位。
最后才会抛出无匹配结果的答案,过程十分繁琐,
引发dos问题的情况
上述的匹配过程虽然繁琐,但是对于计算机的计算量来说仍然是毛毛雨。如果我们想让计算机的计算量也无能为力的话,就需要将重复运算符嵌套起来,让计算量呈指数增长。
比如使用^(a+)+$,然后进行一次错误匹配,在https://regex101.com/ 上面观察所需的步数。
ab 6步
aab 12步
aaab 24步
aaaab 48步
……
aaaaaaaaaab 3072步
……
aaaaaaaaaaaaaaab 98304步
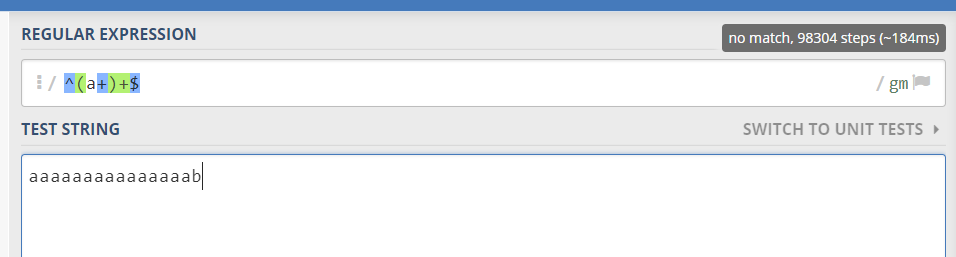
……
aaaaaaaaaaaaaaaaab 393216步
再继续增长该网站就已经抛出catastrophic backtracking的错误了
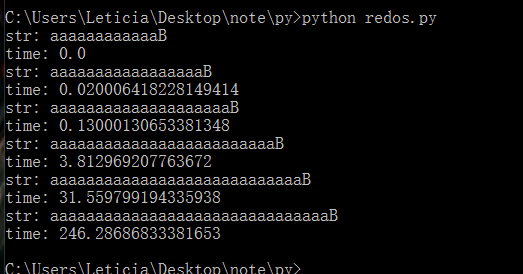
也可以在本地编程观察正则运行所需的时间:
1 | |
可以看到,随着待匹配字符串的长度越来越长,所需的时间呈指数增长,计算机也在运行过程随着cpu的高占用嗡嗡作响。
再让长度这么增长下去,可能需要几天,几个月的运算,在实战渗透测试场景甚至可以多发几个请求占用多个处理器,占用大量的cpu资源,形成dos问题,影响正常业务。
防范
- 规范正则表达式的书写,尽量避免重复运算符嵌套等情况的出现。
- 限制用户输入的长度。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!